Anthropic 突然发布了 Claude Opus 4.7。
没有预热,没有倒计时。直接上线。
这次更新的重心很明确——软件工程。Claude Opus 4.7 在最难的编程任务上提升断档,视觉能力翻了三倍,指令遵循精确到逐字执行。多家早期客户的实测数据显示,过去必须盯着看的复杂代码工作,现在可以放手交给它跑。
如果你正在用 Claude Pro 写代码、做文档、跑 Agent 任务,这次升级直接影响你的日常工作流。
相关教程推荐:
- 需要 Claude Pro 充值?请查看 Claude Pro 充值教程 — 支持支付宝/微信,5 分钟搞定
- 想了解 Claude Code 使用技巧?请参考 Claude Code 创始人分享的 10 个最新用法
Claude Opus 4.7 是什么:这次更新到底改了什么
先说结论。
Claude Opus 4.7 是 Anthropic 最新发布的旗舰模型,即日起在所有 Claude 产品、API、Amazon Bedrock、Google Cloud Vertex AI 和 Microsoft Foundry 上线。
模型 ID:claude-opus-4-7
定价和 Opus 4.6 完全一致:每百万输入 token 5 美元,每百万输出 token 25 美元。对比 Mythos Preview 的 25/125 美元,便宜 5 倍。
这次的核心升级集中在三个方向:
| 升级方向 | 关键变化 |
|---|---|
| 编程能力 | SWE-bench Pro +10.9pp,碾压 Opus 4.6 和 GPT-5.4 |
| 视觉能力 | 图像分辨率从 1568px 拉到 2576px,总像素翻三倍 |
| 指令遵循 | 逐字级精准执行指令,旧 prompt 可能需要重新调整 |
Claude Opus 4.7 编程能力:最难任务上断档提升
这是 Claude Opus 4.7 最大的卖点。
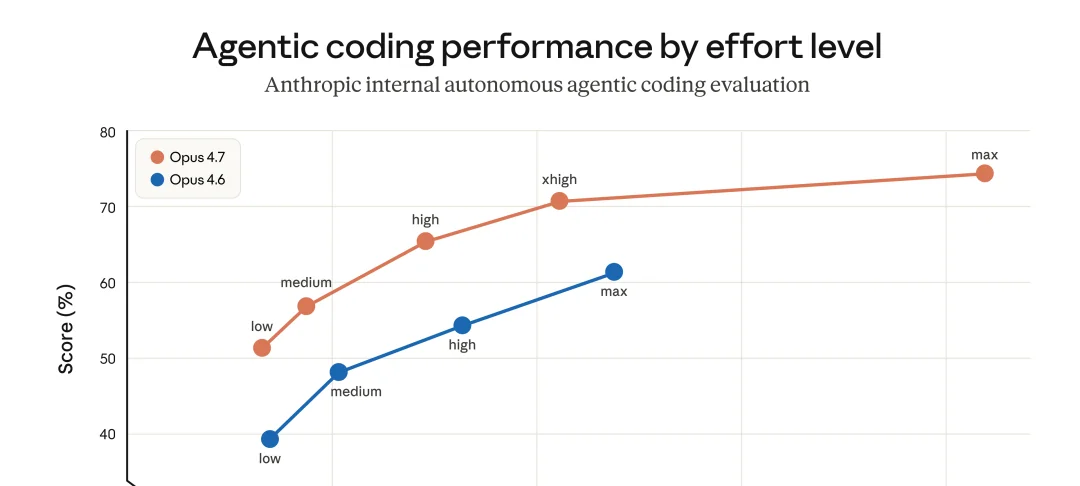
先看官方给出的 agentic 编码性能图——这是这次更新最值得看的一张:
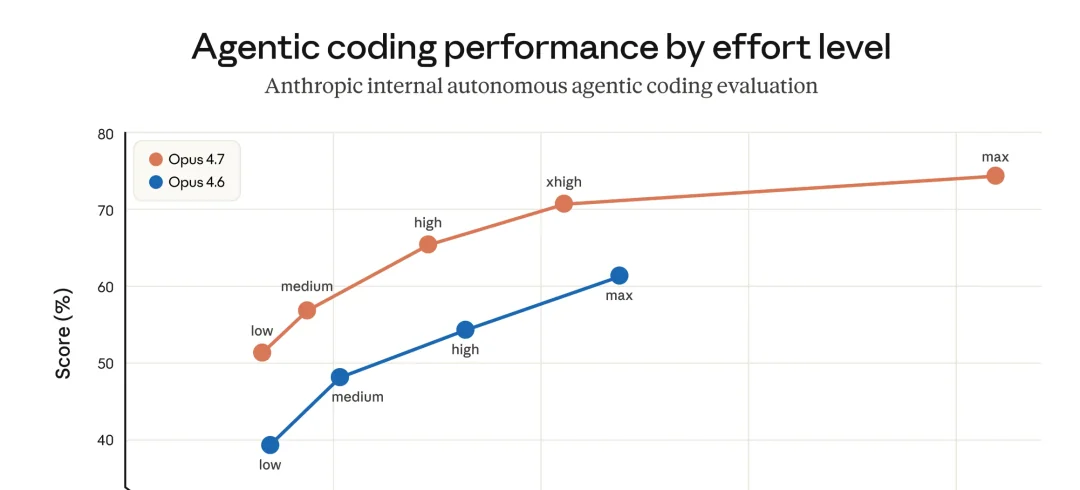 Claude Opus 4.7 vs Opus 4.6 Agentic 编码性能对比图
Claude Opus 4.7 vs Opus 4.6 Agentic 编码性能对比图
横轴是 agent 花掉的 token 总量,纵轴是任务正确率。同一个 effort 档位下,4.7 比 4.6 整体高出 10 分以上。
再看具体的编程 Benchmark 数据:
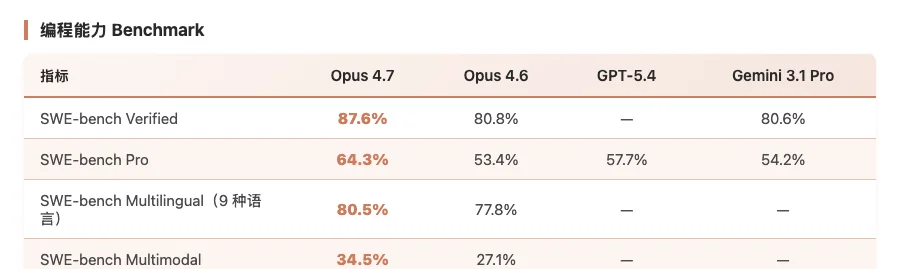 Claude Opus 4.7 编程能力 Benchmark 对比数据
Claude Opus 4.7 编程能力 Benchmark 对比数据
SWE-bench Pro 上 +10.9pp。这个差距在最难的软件工程评测上是断档的。Opus 4.6 只有 53.4%,GPT-5.4 是 57.7%,而 Opus 4.7 直接拉到 64.3%。
多语言和多模态编程也在提升:
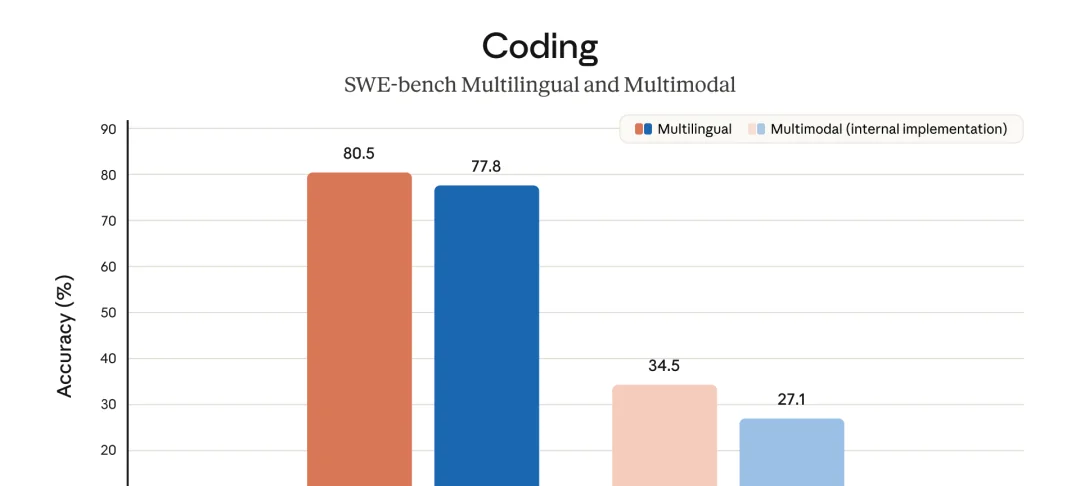 Claude Opus 4.7 SWE-bench Multilingual 和 Multimodal 编程评测
Claude Opus 4.7 SWE-bench Multilingual 和 Multimodal 编程评测
28 家早期客户的实测数据
干数据比任何宣传都有说服力:
| 客户 | 实测结果 |
|---|---|
| GitHub | 93 个任务的编程基准上,比 Opus 4.6 高 13%,其中 4 个任务是 Opus 4.6 和 Sonnet 4.6 都做不了的 |
| Cursor | CursorBench 过 70%,Opus 4.6 是 58% |
| Rakuten | 解决的生产任务是 Opus 4.6 的 3 倍 |
| Notion | 准确率 +14%,token 用更少,工具调用错误减少到三分之一 |
| Cognition(Devin) | 能连贯工作几个小时,不卡在难题上放弃 |
| Imbue | 自主从零构建了一个完整的 Rust TTS 引擎,包括神经网络模型、SIMD 内核、浏览器 demo |
用户反馈里反复出现两个词:长程、自主。过去必须盯着改的那类代码活,现在可以放手让它跑。
如果你在用 Claude Code,这次升级体验会最明显。关于 Claude Code 的高效用法,可以参考 Claude Code 创始人分享的 10 个最新用法,搭配 Opus 4.7 效果更好。
Claude Opus 4.7 视觉能力:分辨率翻三倍
这是第二大升级。
Claude Opus 4.7 支持最长边达 2576 像素的图片输入,总像素约 375 万,是此前 Claude 系列的三倍以上。这是模型层的变化,不需要任何 API 参数开关,直接送高分辨率图过去就行。
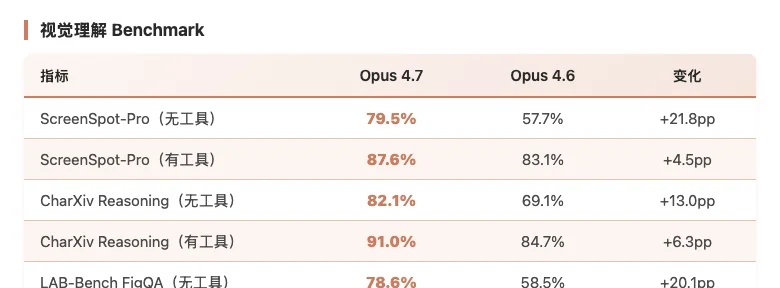 Claude Opus 4.7 视觉理解 Benchmark 对比数据
Claude Opus 4.7 视觉理解 Benchmark 对比数据
ScreenSpot-Pro 是一个关键测试——让 AI 从真实软件截图里精准点击目标 UI 元素,哪怕目标只占屏幕 0.1%。Opus 4.7 从 57.7% 跳到 79.5%。
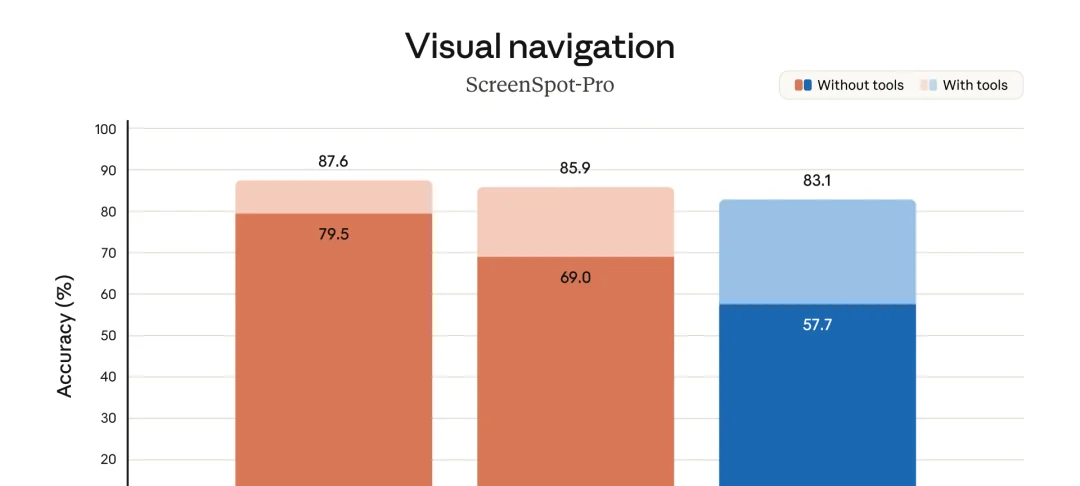 Claude Opus 4.7 ScreenSpot-Pro 视觉导航高分辨率对比
Claude Opus 4.7 ScreenSpot-Pro 视觉导航高分辨率对比
XBOW 的安全视觉测试更夸张:视觉敏锐度基准从 Opus 4.6 的 54.5% 飙升到 Opus 4.7 的 98.5%。
这意味着什么?computer-use agent 读密集截图、复杂图表数据抽取、需要像素级参考的工作,都有了质的飞跃。
Claude Opus 4.7 vs GPT-5.4:关键 Benchmark 横向对比
先看全景。Opus 4.7、Opus 4.6、GPT-5.4、Gemini 3.1 Pro 和 Mythos Preview 的横向对比:
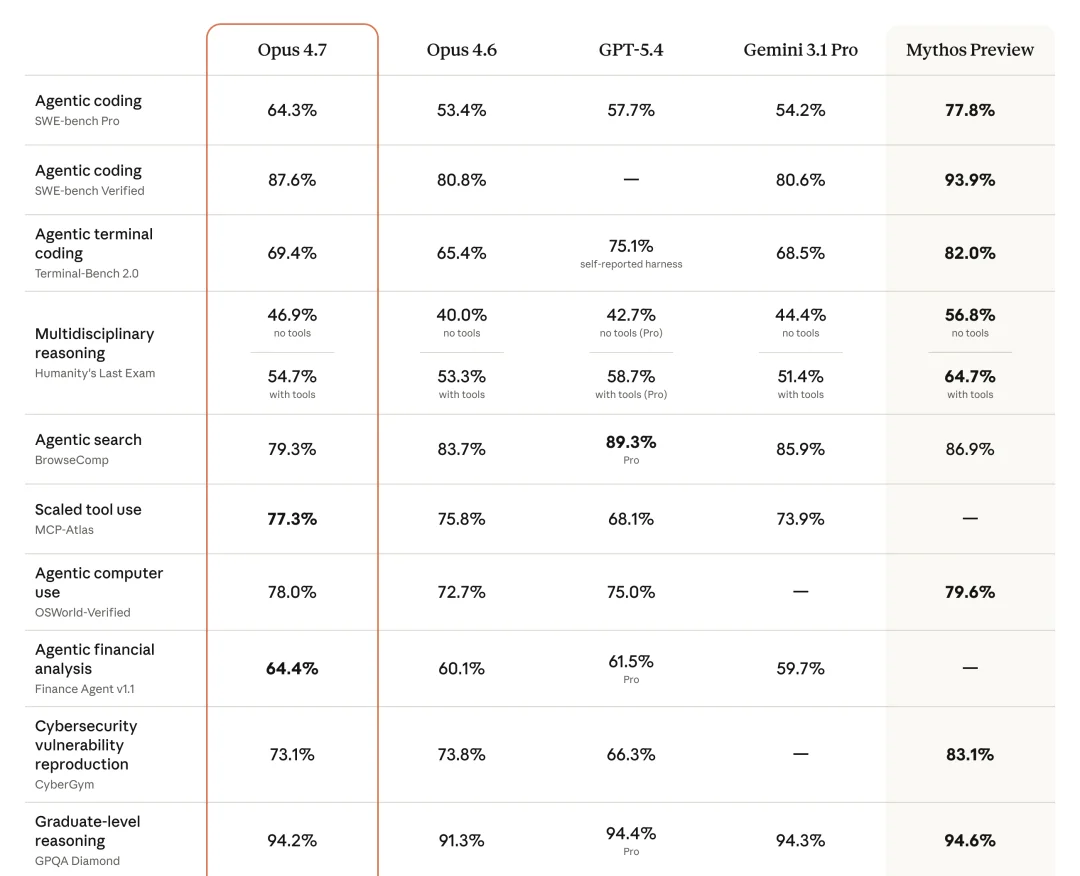 Claude Opus 4.7 各项 Benchmark 全景对比评测数据
Claude Opus 4.7 各项 Benchmark 全景对比评测数据
14 项评测中,9 项领先所有公开可用模型。拆开看关键项目:
| Benchmark | Claude Opus 4.7 | GPT-5.4 | Opus 4.6 | 说明 |
|---|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | 53.4% | 最难编程任务,断档领先 |
| ScreenSpot-Pro | 79.5% | — | 57.7% | 视觉导航,翻倍级提升 |
| OfficeQA Pro | 80.6% | 51.1% | 57.1% | 文档理解,远甩 GPT-5.4 |
| OSWorld | 78.0% | 75.0% | — | 真实桌面操作 |
| GPQA Diamond | 75.5% | 73.3% | 69.4% | 博士级推理 |
| GDPval-AA | 领先 79 ELO | 基准 | — | 跨行业知识工作 |
结论很清楚:Claude Opus 4.7 在编程、视觉、文档理解、Agent 操作上全面领先 GPT-5.4。推理能力两者接近,搜索检索上 Opus 4.6 反而更强。
Opus 4.7 编程、视觉、Agent 全面升级,Claude Pro 用户可直接使用最新模型
Claude Opus 4.7 知识工作与推理能力
编程之外,Claude Opus 4.7 在知识工作上的提升同样值得关注。
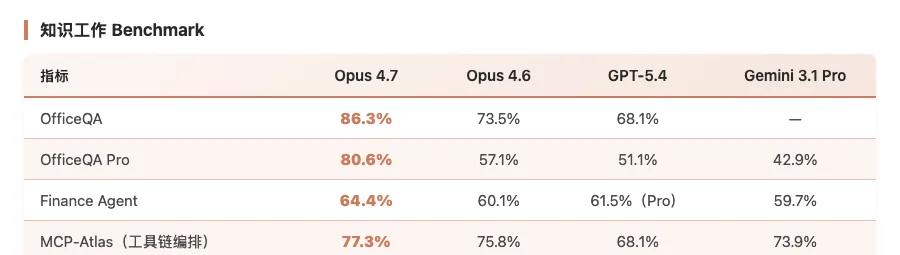 Claude Opus 4.7 知识工作 Benchmark 对比评测
Claude Opus 4.7 知识工作 Benchmark 对比评测
OfficeQA Pro 从 57.1% 升到 80.6%(+23.5pp),测的是读长文档、电子表格、幻灯片并精准回答。GPT-5.4 才 51.1%,Gemini 3.1 Pro 才 42.9%。
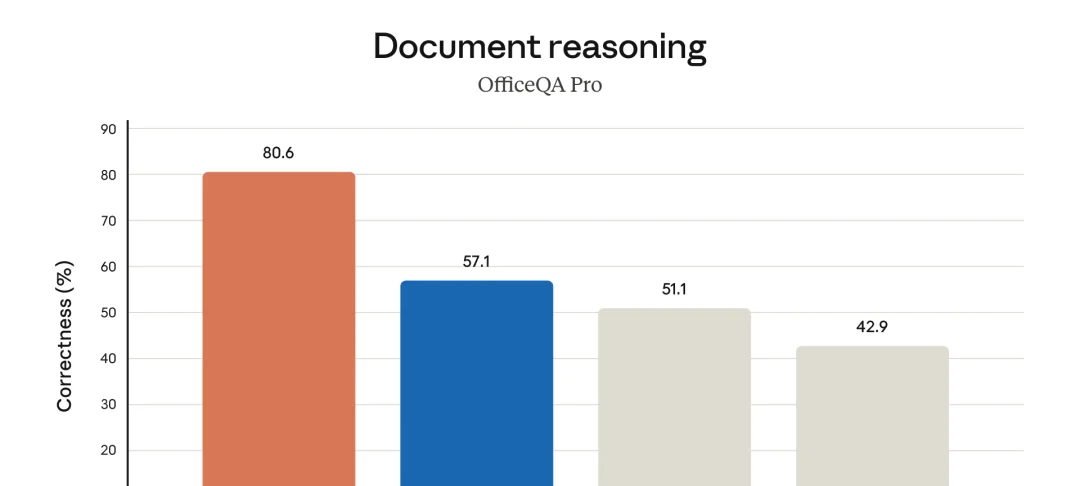 Claude Opus 4.7 OfficeQA Pro 文档推理四模型横向对比
Claude Opus 4.7 OfficeQA Pro 文档推理四模型横向对比
GDPval-AA 是第三方 Artificial Analysis 做的独立评测,覆盖 44 个职业、9 大行业、220 个真实工作任务。Opus 4.7 对 GPT-5.4 顶配的 pairwise 胜率 61.2%(领先 79 个 ELO 分)。
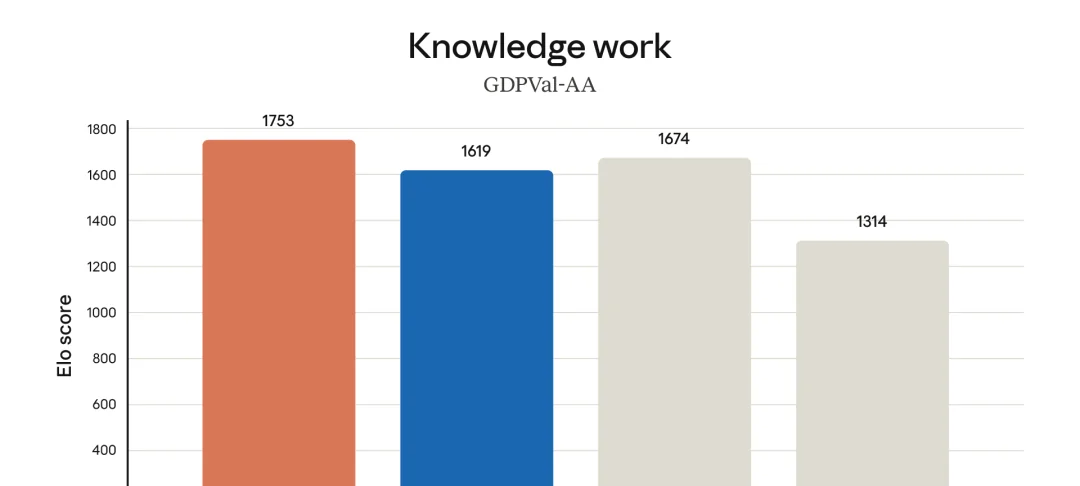 Claude Opus 4.7 GDPVal-AA 知识工作 ELO 评分对比
Claude Opus 4.7 GDPVal-AA 知识工作 ELO 评分对比
推理能力方面:
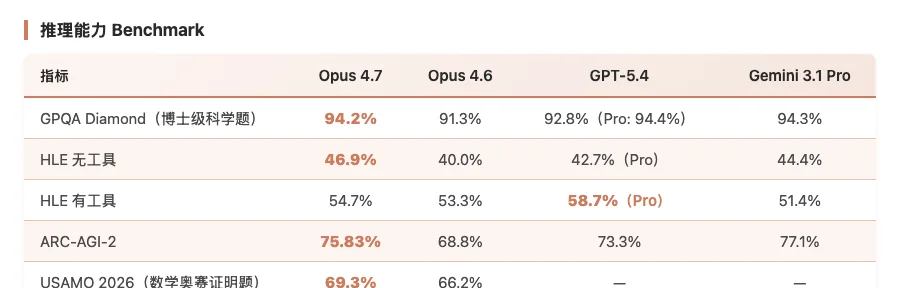 Claude Opus 4.7 推理能力 Benchmark 对比数据
Claude Opus 4.7 推理能力 Benchmark 对比数据
GPQA Diamond 在博士级难度下已经几乎触顶。USAMO 2026 是完整的数学证明过程,不是选择题。ARC-AGI-2 比 GPT-5.4 的 73.3% 高,但被 Gemini 3.1 Pro 的 77.1% 压了一头。
Databricks 的反馈也很直接:文档推理错误率比 Opus 4.6 降低 21%。
Claude Opus 4.7 Agent 自主能力:真的在操作电脑
 Claude Opus 4.7 Agent 自主能力 Benchmark 对比数据
Claude Opus 4.7 Agent 自主能力 Benchmark 对比数据
OSWorld 让 AI 在真实 Ubuntu 虚拟机里编辑文档、管文件、上网、敲快捷键。Opus 4.7 拿下 78.0%,领先 GPT-5.4 的 75.0%。
VendingBench 模拟一年小店经营——找供应商、谈价格、管库存、定价策略。Opus 4.7 Max 档赚到 10,937 美元,刷新 SOTA。
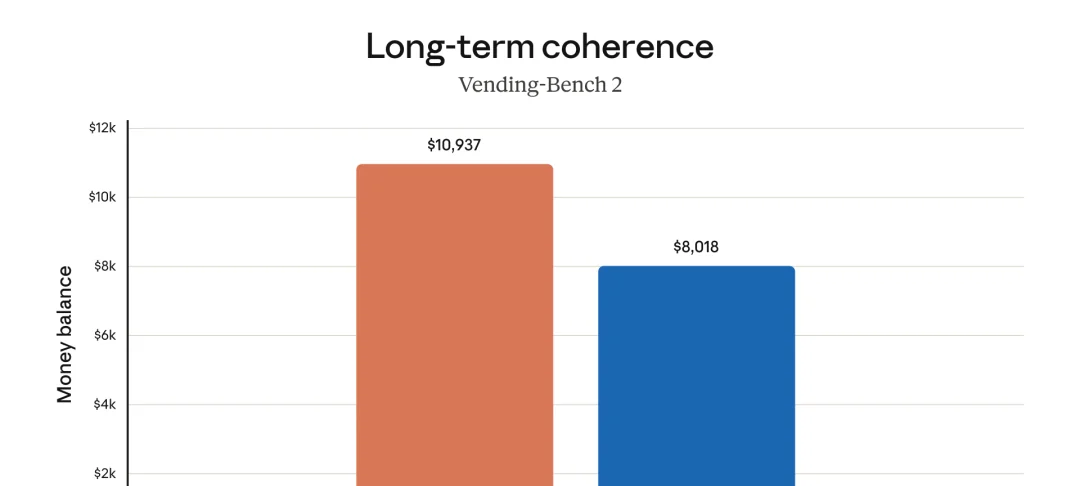 Claude Opus 4.7 VendingBench 长程连贯性评测结果
Claude Opus 4.7 VendingBench 长程连贯性评测结果
不过要注意,BrowseComp(网页搜索检索)上 Opus 4.6 反而更好(83.7% vs 79.3%)。Anthropic 自己也说了,Opus 4.6 在这个 benchmark 上的 test-time compute 效率更高。如果你的场景是搜索密集型的,建议两个版本都试试。
Claude Opus 4.7 指令遵循:逐字执行带来的新问题
这个特性值得单独说。
Opus 4.7 的指令遵循能力有了实质性提升。它会逐字执行你的每一条指令。
听起来是好事对吧?但这里有个坑。
原来的模型会宽松解读或跳过部分指令,你可能已经习惯了那种"差不多就行"的交互方式。Opus 4.7 不会再帮你"脑补"了。你写什么,它就做什么。
这意味着:为老模型写的提示词,在 Opus 4.7 上可能产生意外结果。
升级之后,建议先拿小任务测一下现有 prompt。发现问题不要慌,大概率不是模型变差了,而是它太"听话"了。
记忆能力也有改善。Opus 4.7 更善于使用文件系统存储关键笔记,能在多个长时段任务之间保持记忆,接手新任务时需要的前置上下文更少。
Claude Opus 4.7 新功能:xhigh、task budgets、/ultrareview
这次同步上线了几个新功能:
xhigh effort 档位。 原来是 low / medium / high / max 四档,这次在 high 和 max 之间加了一个 xhigh。Claude Code 默认 effort 已经拉到 xhigh。官方建议编程和 agentic 场景用 high 或 xhigh 起步。
task budgets 公测。 API 端新功能,让开发者给 Claude 设置 token 预算上限,让它在长任务里自己分配优先级。配合 effort 参数一起用,控制粒度更细。
/ultrareview 命令。 Claude Code 新增的斜杠命令,可以专门读取代码变更,跑一个独立的 review 会话,标出仔细审查者会发现的 Bug 和设计问题。Pro 和 Max 用户各有 3 次免费体验机会。更多 Claude Code 使用技巧可以参考 Claude Code 创始人分享的 10 个最新用法。
Auto mode 下放到 Max 用户。 Auto 模式是 --dangerously-skip-permissions 和默认每步都问之间的中间档:安全操作自动放行,危险操作拦下来让 Claude 换方案。长任务跑起来减少打扰,同时比跳过所有权限更安全。
从 Opus 4.6 升级到 Opus 4.7:迁移注意事项
如果你正在用 Opus 4.6,升级之前有三个变化必须知道。
第一,tokenizer 换了。 同样的输入文本,新 tokenizer 下的 token 数大约是旧版的 1.0 到 1.35 倍,具体取决于内容类型。
第二,高 effort 档想得更多。 尤其是 agentic 场景里靠后的轮次,Opus 4.7 在较高 effort 级别下会产生更多推理过程。好处是硬题可靠性上去了,代价是更多输出 token。
 Claude Opus 4.7 不同 effort 档位编码效率对比
Claude Opus 4.7 不同 effort 档位编码效率对比
第三,指令跟随强度大幅提升。 这个最容易踩坑。为老模型写的 prompt,Opus 4.7 会严格按字面执行。升级时 prompt 要重新调一遍。
控制 token 用量的方法:调整 effort 参数、设置 task budgets、或者在 prompt 里提示模型更简洁作答。Anthropic 内部测试显示,在编程评估任务中,各 effort 级别下的综合 token 消耗仍有改善,但建议在你的真实流量上单独测量。
Claude Opus 4.7 定价与使用方式
Claude Opus 4.7 的定价和 Opus 4.6 完全一致:
| 项目 | 价格/信息 |
|---|---|
| API 输入 | 5 美元 / 百万 token |
| API 输出 | 25 美元 / 百万 token |
| 模型 ID | claude-opus-4-7 |
| 可用平台 | Claude 全系产品、API、Bedrock、Vertex AI、Foundry |
| Claude Code 默认 effort | xhigh |
对比 Mythos Preview 的 25/125 美元,便宜整整 5 倍。
对于普通用户来说,最直接的使用方式是通过 Claude Pro 订阅。Claude Pro 月付 20 美元,就能在 Claude.ai 网页版、桌面端和移动端使用包括 Opus 4.7 在内的所有模型。
如果你还没开通 Claude Pro,或者被海外支付卡住了,可以参考 2026 最新 Claude 充值教程,里面把代充值、成品号、合租三种方案都说清楚了。也可以直接通过 ClaudePro 完成 Claude Pro 充值,支持支付宝和微信支付。
支持支付宝/微信支付,国内用户 5 分钟完成 Claude Pro 订阅开通
Claude Opus 4.7 安全策略:Project Glasswing 与对齐评估
这次安全设计要配合 Project Glasswing 一起看。
Anthropic 联合 AWS、苹果、博通、思科、CrowdStrike、Google、摩根大通、微软、NVIDIA、Palo Alto Networks 等成立了 Project Glasswing。背景是 Claude Mythos Preview 在漏洞挖掘上达到了超过大多数安全专家的水平——已经在每个主流 OS 和主流浏览器里找出了 0-day 漏洞。
Opus 4.7 是为这个安全问题准备的第一个对外模型。训练过程中有意降低了网络安全攻击能力,发布时带上了自动检测和拦截高风险请求的护栏。做合法安全研究的人可以申请加入 Cyber Verification Program。
对齐评估总体结论:Opus 4.7 比 Opus 4.6 和 Sonnet 4.6 好一些。官方原话是 "largely well-aligned and trustworthy, though not fully ideal in its behavior"。诚实性和抵御恶意提示注入攻击方面有所改进。
常见问题
Claude Opus 4.7 和 Opus 4.6 有什么区别?
最大的区别在编程能力。SWE-bench Pro 上 Opus 4.7 得 64.3%,比 Opus 4.6 的 53.4% 高出 10.9 个百分点。视觉分辨率翻三倍,指令遵循精确度大幅提升。定价不变。
Claude Opus 4.7 比 GPT-5.4 强吗?
看场景。编程(SWE-bench Pro 64.3% vs 57.7%)、文档理解(OfficeQA Pro 80.6% vs 51.1%)、桌面操作(OSWorld 78.0% vs 75.0%)上 Opus 4.7 明显领先。推理能力两者接近。搜索检索上 Opus 4.6 反而更强。
Claude Opus 4.7 怎么用?
开发者通过 API 调用,模型 ID 为 claude-opus-4-7。普通用户可以通过 Claude Pro 订阅(20 美元/月)在 Claude.ai 上直接使用。Claude Code 用户升级后默认使用 xhigh effort 档位。
Claude Opus 4.7 多少钱?
API 定价:每百万输入 token 5 美元,每百万输出 token 25 美元,和 Opus 4.6 一致。Claude Pro 订阅价格不变,月付 20 美元,年付 200 美元。
升级到 Opus 4.7 需要改 prompt 吗?
大概率需要。Opus 4.7 的指令遵循能力强了很多,会逐字执行你的指令。为老模型写的 prompt,可能产生意外结果。建议先用小任务测试现有 prompt,再逐步切换。
国内用户怎么用上 Claude Opus 4.7?
Anthropic 官方不支持中国大陆直接访问。可以通过 Cursor、Amazon Bedrock 等合规路径使用 Opus 4.7 API。如果你想在 Claude.ai 上使用,需要开通 Claude Pro 订阅。国内用户可以通过 ClaudePro 完成 Claude Pro 充值,支持支付宝和微信支付。
关于 Claude Pro 订阅的更多细节,比如Claude禁止使用OpenClaw,建议提前了解清楚,避免踩坑。
相关教程推荐
如果你正在使用 Claude 或其他 AI 工具,以下资源可能对你有帮助:
- Claude Pro 充值:Claude Pro 国内充值教程 — 支持支付宝/微信,国内用户首选
- Claude 订阅指南:2026 最新 Claude 充值教程:Claude Pro 怎么订阅 — 代充值、成品号、合租三种方案全解析
- Claude Code 使用技巧:Claude Code 创始人分享的 10 个最新用法 — 高效使用 Claude Code 的核心工作流
相关链接:
- ClaudePro(Claude Pro 充值):https://claudepro.org/
- Claude 官方公告:https://www.anthropic.com/news/claude-opus-4-7
- Claude Opus 4.7 System Card:https://www.anthropic.com/claude-opus-4-7-system-card